
← All posts
Agentic AI in Digital Libraries — What Autonomy Promises and What It Actually Requires
Something shifted in AI deployment in 2025 that has not yet been fully absorbed by the digital library field. The shift is not in model capability — though model capability continued to improve — but in model architecture. The dominant mode of AI use moved from single-turn question answering toward what the field now calls agentic AI: systems in which a large language model is coupled with tools, memory, planning mechanisms, and the ability to take sequences of actions across multiple steps without requiring human input at each step. The distinction is not cosmetic. A single-turn LLM responds to a query. An agentic LLM receives a goal and pursues it — calling APIs, reading documents, writing code, querying databases, revising its approach based on what it finds, and continuing until it determines that the goal has been achieved or that it cannot achieve it. The industry has adopted a compressed formulation: classic LLMs approximate System 1 thinking — fast, reactive, pattern-matching. Agentic LLMs introduce System 2 — deliberate, goal-directed, operating across time. For digital library applications, this architectural shift is both an opportunity and a genuinely serious governance challenge. The opportunity is obvious: agentic systems can automate cataloging workflows, perform systematic literature searches, synthesise content across distributed repositories, maintain metadata quality at scale, and support user research tasks in ways that single-turn models cannot. The governance challenge is less widely discussed and more urgent than the field has yet acknowledged. What Agentic Systems Can Do in Library Contexts The Agent4DL system, presented at the 26th International Conference on Asia-Pacific Digital Libraries in December 2024, offers the clearest current demonstration of what agentic architecture enables in digital library contexts specifically. Agent4DL uses LLM-based agents to simulate user search behaviour in digital libraries — modelling realistic, diverse user interactions at scale for the purpose of evaluating and improving information retrieval systems. The significance of this application is not the simulation itself but what it demonstrates about agentic capability: the system can navigate a digital library interface, formulate queries, evaluate results, reformulate queries based on what the results contain, and produce an account of the search process that reflects the kind of multi-step reasoning that distinguishes expert information seeking from keyword lookup. This is not something a single-turn LLM can do. It requires the planning and tool-use capabilities that define agentic architecture. More directly operational applications are either deployed or in active development across the field. Automated metadata enrichment agents can traverse a repository, identify records with incomplete or inconsistent metadata, retrieve relevant context from external sources, and propose or apply corrections — replicating, at machine speed, work that metadata librarians currently perform manually. Literature synthesis agents can receive a research question, retrieve relevant documents from multiple repositories, assess their relevance and quality, and produce a structured summary with citations — a workflow that currently requires hours of expert human effort. The MCP-FHIR framework published at arXiv in 2025 — integrating the Model Context Protocol with FHIR-structured electronic health records for clinical decision support — represents a specific application of agentic architecture to the health data library context: an LLM agent that can navigate a patient's EHR, retrieve relevant clinical information, and synthesise it for a clinician's use. The paper identifies a substantial gap between data availability and meaningful interpretation, which agentic architecture is specifically designed to bridge. What the Research Identifies as the Core Problems The 2025 AAAI Presidential Panel on the Future of AI Research, and the subsequent February 2026 analysis presented at the AAAI Bridge Program on Advancing LLM-Based Multi-Agent Collaboration, identify three core unsolved problems in agentic AI deployment that are directly relevant to digital library contexts. Reliability and grounding. Agentic systems often struggle to connect their language-based reasoning with the actual state of the world. They may generate plausible but false information, or take actions that do not reflect real conditions, particularly when using tools or interacting with digital environments. In a library context, this means an agent performing automated cataloging may assign metadata that is structurally valid but semantically incorrect — producing a record that passes automated quality checks but misleads future users. The 2025 analysis describes this as "cascading errors": an incorrect action at one step propagates through subsequent steps, producing an output that is wrong in ways that are difficult to trace back to the original failure point. Evaluation. There are no agreed methods for assessing the performance of agentic systems across the range of tasks they are asked to perform. Benchmark evaluations exist for specific, well-defined tasks — question answering, summarisation, code generation. They do not exist, in any standardised form, for the kind of multi-step, goal-directed tasks that agentic library systems would perform. A library that deploys an agentic cataloging system cannot currently determine, from published research, how frequently that system will produce errors, what kinds of errors are most likely, or how to design monitoring that would detect them. Interpretability. As agents become more capable, understanding why a specific sequence of actions was taken becomes increasingly difficult. The 2025 survey on agentic AI published in ResearchGate identifies what it calls the "interpretability paradox": increasing agency and autonomy tend to obscure transparency. An agent that takes twenty sequential actions to complete a cataloging task does not provide the same kind of auditable decision trail that a human cataloger does. If the output is wrong, diagnosing why requires understanding which of the twenty actions introduced the error — a non-trivial reverse-engineering problem. The Governance Infrastructure Libraries Need Before Deploying Agents The digital library field has not, as a community, established the governance frameworks that responsible agentic AI deployment requires. This is not a criticism but a description of where the field currently stands relative to what deployment requires. Three frameworks are needed and largely absent. Human-in-the-loop protocols calibrated to task risk. Not all library tasks warrant the same level of human oversight for agentic operations. An agent that proposes metadata enrichments for human review before application carries very different risk than an agent that applies changes directly. The field needs task-specific protocols that define where autonomous action is appropriate and where human review is required — calibrated to the consequences of error rather than to the technical capability of the system. Audit trail infrastructure. Agentic systems need to produce records of their actions that are sufficient for post-hoc diagnosis of errors. This is not merely a technical requirement but an institutional one: libraries have legal and professional obligations around the integrity of their records. An agentic system that modifies catalog records without producing an auditable trail of what it changed and why is not compatible with those obligations, regardless of how capable the system is. Institutional accountability structures. When an agentic system makes an error that affects research discovery — when it misclassifies a set of records, suppresses relevant results through incorrect metadata, or introduces systematic bias through the training data its decisions reflect — who is responsible? The question is not rhetorical. It has legal, professional, and ethical dimensions that the library community needs to address before agentic systems are widely deployed, not after. The Right Frame for the Field's Next Step The JCDL community's track on AI for Libraries — retrieval-augmented cataloging, automated metadata generation, conversational access, model provenance — is where these questions will be most directly addressed at the 2026 conference. The questions are not whether agentic systems can be useful in library contexts. The Agent4DL research and the MCP-FHIR framework and the automated metadata enrichment prototypes under development at multiple institutions all demonstrate that they can. The questions are what governance infrastructure needs to exist before deployment can be responsible, what evaluation frameworks the field needs to develop to assess agentic system performance on library-specific tasks, and what the institutional accountability structures look like when autonomous systems become part of the library's operational infrastructure. These are questions the field is equipped to answer. They require the same combination of technical rigour, professional ethics, and long-term institutional thinking that has characterised the best digital library work since the first JCDL convened in Tucson in 2004. The architecture has changed. The questions have not.
Keep reading
More from AI technology
AI technology
Jun 8, 2026
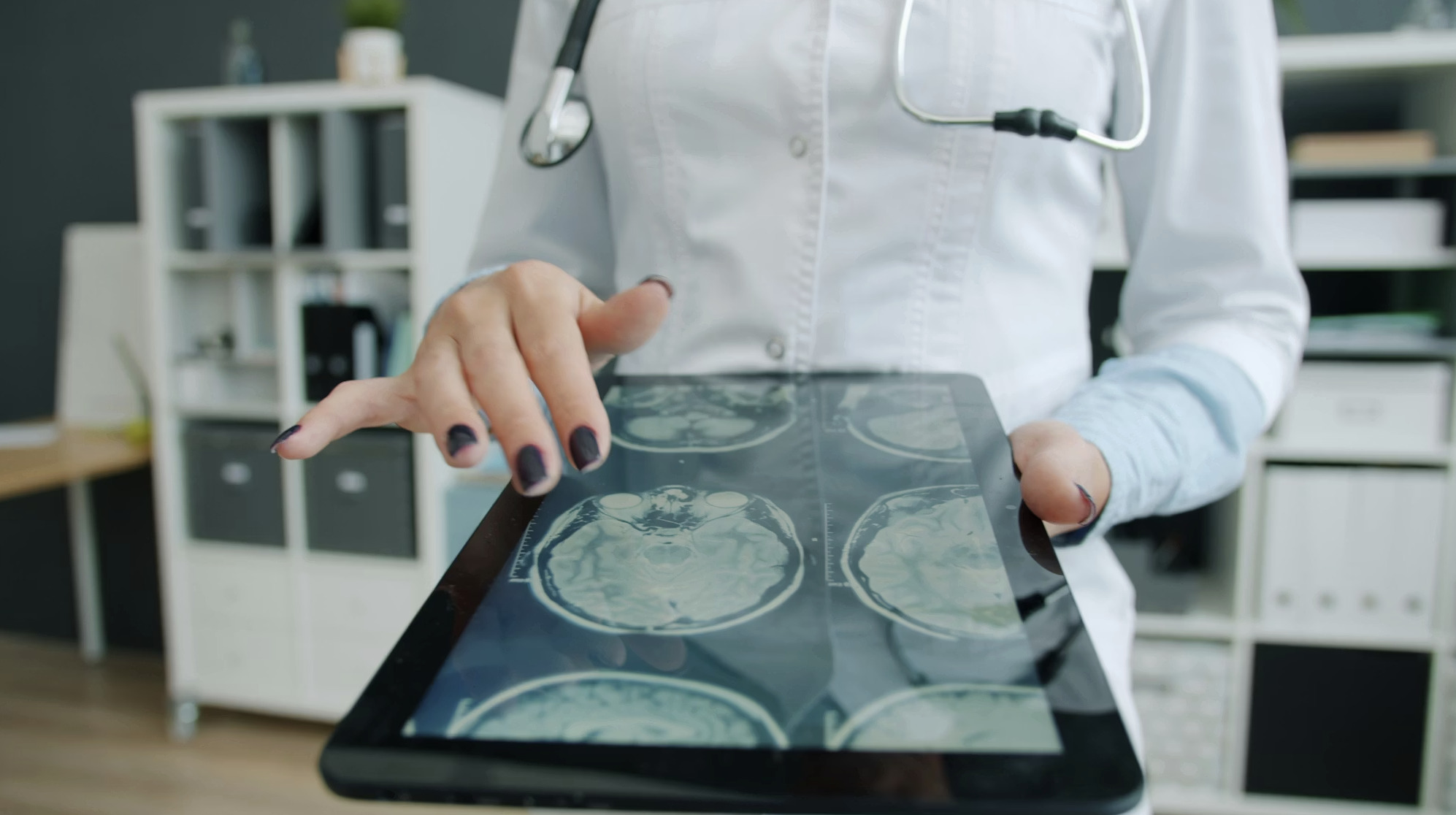
How RAG and LLMs Are Transforming Library Discovery
For two centuries, the front door to a library's knowledge was a list. You asked a question, and the system handed back a set of candidates — catalogue cards,…
By Allison Powell Read →
AI technology
May 5, 2026
RAG Is Not a Cure — What Retrieval-Augmented Generation Actually Fixes in Biomedical Libraries
Retrieval-Augmented Generation has become the consensus answer to the question that biomedical information professionals and clinical AI developers have been a…
By Kazunari Sugiyama Read →

AI technology
May 4, 2026
FAIR Was Never Built for Machine Learning
The FAIR Guiding Principles — Findable, Accessible, Interoperable, Reusable — emerged from a 2014 workshop at the Lorentz Center in Leiden, were formalised by…
By Allison Powell Read →